High-level working of Kubernetes Cluster:
API-Server is the brain of the Kubernetes cluster. Nothing happens in the cluster without the blessing of the API-server. For example, a REST request is sent to the API server when you run “kubectl get pod” internally. Similarly, the API-server facilitates everything when you delete, create, and modify any Kubernetes object, Think of any action in the Kubernetes Cluster; the API-server enables everything. All the states are stored in the ETCD database(see this), and only API-server is allowed to talk to the ETCD; this means, for fetching or updating any state of any object, requesting an API server is required.
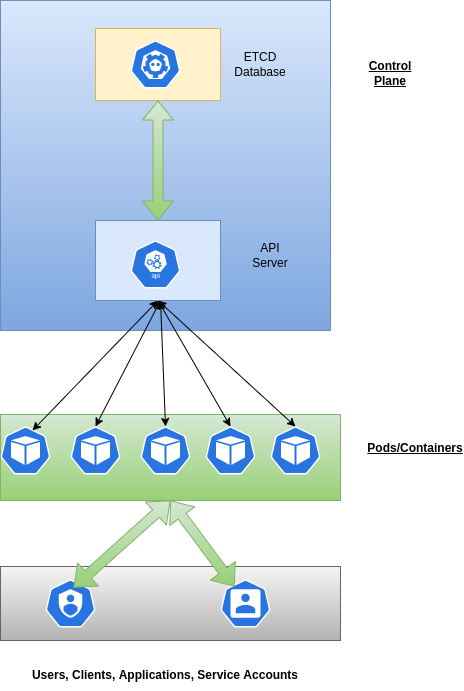
However, it is essential to note that kubectl is not the only client making changes in the cluster. For example, their respective controllers manage pods that are part of replica sets, deployments, stateful sets, and daemon sets. In addition, these controllers are responsible for keeping them up and running and managing their scaling. Similarly, kubelet is responsible for keeping the node healthy and informing any node-health issue on the API server. Similarly, a malicious user or service account could make changes using kubectl. There could be thousands of nodes in the cluster, meaning thousands of kubelets. Likewise, many other players are changing the states of the objects in the cluster.
Log Lifecycle:
The steps to enable audit logs are simple if the concept of the lifecycle of the logs is clear. So, before going through the procedure to enable the audit logs, here is the log lifecycle in straightforward words. When the request reaches the API Server it go through multiple stages within the API Server, as a cluster administrator may decide which stage should be captured for a particular type of resource.
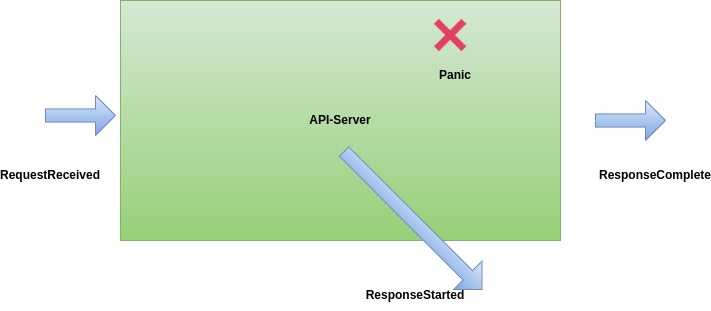
The lifecycle of the request is divided into the following stages:
- RequestReceived: A request will enter into the API server in this stage. The API Server has not yet started processing the request.
- ResponseStarted: In this stage, the API server will start processing the received request in the previous stage. Response headers are sent already, but the body is not completed. This is a particular case only for long-running requests, like “kubectl with watch enabled.” E.g., kubectl get pod -w
- ResponseComplete: In this stage, the API server has completed the response for the received request. This is a critical stage where the requested changes are reflected.
- Panic: When some panic happens. Kubernetes is written in Golang, and in Golang, panic means some catastrophic error happened. If you want to limit to error-only logs, then use this option. However, only logs during the panic stage may not be enough to make sense of the issue.